

在数字化时代,我们常常需要从网络上获取信息并有效地利用这些信息。Python作为一门广泛应用的编程语言,在自动化处理数据和文档方面展现出了极大的潜力。特别是在需要将网页内容转换为PDF文件以便离线阅读或保存的情况下,掌握一种有效的方法变得尤为重要。
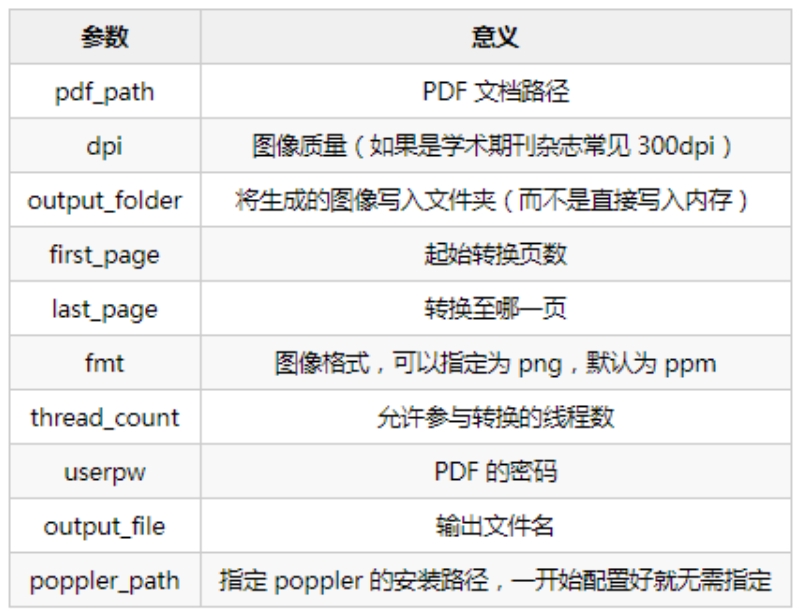
要使用Python从URL读取内容并生成PDF,可以使用多个库,其中pdfkit和weasyprint是两个非常受欢迎的选择。这两个库都可以将HTML转换为PDF,但是pdfkit基于wkhtmltopdf,而weasyprint有自己的渲染引擎。以下是如何使用这两个库实现目标的示例:
使用pdfkit
首先,你需要安装wkhtmltopdf,这可以在其官方网站上找到安装指南。然后,安装pdfkit库:
使用pdfkit的示例代码:
使用weasyprint
weasyprint是一个纯Python库,无需额外的系统依赖。你可以通过以下命令安装:
使用weasyprint的示例代码:
注意事项
-
pdfkit需要wkhtmltopdf二进制文件在系统路径中可访问,或者直接指定configuration参数。 -
weasyprint可能在渲染某些复杂的CSS或JavaScript生成的内容时不如pdfkit全面。 -
对于
pdfkit,如果wkhtmltopdf不在路径中,你需要手动指定配置:
总结
根据你的具体需求和环境,可以选择pdfkit或weasyprint。如果需要高度的HTML和CSS兼容性,weasyprint可能是一个更好的选择。如果环境中已经安装了wkhtmltopdf,pdfkit则提供了一个更直接的接口。

 QQ客服专员
QQ客服专员 电话客服专员
电话客服专员